The prototypes for these intrinsics are in the ia64intrin.h header file.
For detailed information about an intrinsic, click on the intrinsic name in the following table.
| Intrinsic | Operation | Corresponding Itanium Instruction |
|---|---|---|
| _m64_czx1l | Compute Zero Index | czx1.l |
| _m64_czx1r | Compute Zero Index | czx1.r |
| _m64_czx2l | Compute Zero Index | czx2.l |
| _m64_czx2r | Compute Zero Index | czx2.r |
| _m64_mix1l | Mix | mix1.l |
| _m64_mix1r | Mix | mix1.r |
| _m64_mix2l | Mix | mix2.l |
| _m64_mix2r | Mix | mix2.r |
| _m64_mix4l | Mix | mix4.l |
| _m64_mix4r | Mix | mix4.r |
| _m64_mux1 | Permutation | mux1 |
| _m64_mux2 | Permutation | mux2 |
| _m64_padd1uus | Parallel add | padd1.uus |
| _m64_padd2uus | Parallel add | padd2.uus |
| _m64_pavg1_nraz | Parallel average | pavg1 |
| _m64_pavg2_nraz | Parallel average | pavg2 |
| _m64_pavgsub1 | Parallel average subtract | pavgsub1 |
| _m64_pavgsub2 | Parallel average subtract | pavgsub2 |
| _m64_pmpy2r | Parallel multiply | pmpy2.r |
| _m64_pmpy2l | Parallel multiply | pmpy2.l |
| _m64_pmpyshr2 | Parallel multiply and shift right | pmpyshr2 |
| _m64_pmpyshr2u | Parallel multiply and shift right | pmpyshr2.u |
| _m64_pshladd2 | Parallel shift left and add | pshladd2 |
| _m64_pshradd2 | Parallel shift right and add | pshradd2 |
| _m64_psub1uus | Parallel subtract | psub1.uus |
| _m64_psub2uus | Parallel subtract | psub2.uus |
__int64 _m64_czx1l(__m64 a)
The 64-bit value a is scanned for a zero element from the most significant element to the least significant element, and the index of the first zero element is returned. The element width is 8 bits, so the range of the result is from 0 - 7. If no zero element is found, the default result is 8.
__int64 _m64_czx1r(__m64 a)
The 64-bit value a is scanned for a zero element from the least significant element to the most significant element, and the index of the first zero element is returned. The element width is 8 bits, so the range of the result is from 0 - 7. If no zero element is found, the default result is 8.
__int64 _m64_czx2l(__m64 a)
The 64-bit value a is scanned for a zero element from the most significant element to the least significant element, and the index of the first zero element is returned. The element width is 16 bits, so the range of the result is from 0 - 3. If no zero element is found, the default result is 4.
__int64 _m64_czx2r(__m64 a)
The 64-bit value a is scanned for a zero element from the least significant element to the most significant element, and the index of the first zero element is returned. The element width is 16 bits, so the range of the result is from 0 - 3. If no zero element is found, the default result is 4.
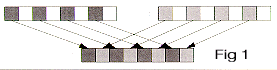
__m64 _m64_mix1l(__m64 a, __m64 b)
Interleave 64-bit quantities a and b in 1-byte groups, starting from the left, as shown in Figure 1, and return the result.
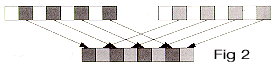
__m64 _m64_mix1r(__m64 a, __m64 b)
Interleave 64-bit quantities a and b in 1-byte groups, starting from the right, as shown in Figure 2, and return the result.
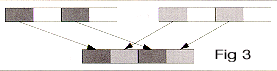
__m64 _m64_mix2l(__m64 a, __m64 b)
Interleave 64-bit quantities a and b in 2-byte groups, starting from the left, as shown in Figure 3, and return the result.
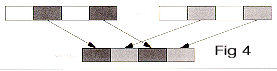
__m64 _m64_mix2r(__m64 a, __m64 b)
Interleave 64-bit quantities a and b in 2-byte groups, starting from the right, as shown in Figure 4, and return the result.
__m64 _m64_mix4l(__m64 a, __m64 b)
Interleave 64-bit quantities a and b in 4-byte groups, starting from the left, as shown in Figure 5, and return the result.

__m64 _m64_mix4r(__m64 a, __m64 b)
Interleave 64-bit quantities a and b in 4-byte groups, starting from the right, as shown in Figure 6, and return the result.

__m64 _m64_mux1(__m64 a, const int n)
Based on the value of n, a permutation is performed on a as shown in Figure 7, and the result is returned. Table 1 shows the possible values of n.
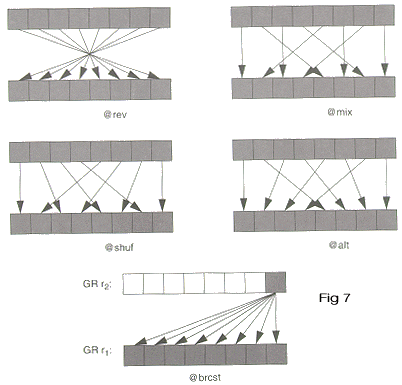
| n | |
|---|---|
| @brcst | 0 |
| @mix | 8 |
| @shuf | 9 |
| @alt | 0xA |
| @rev | 0xB |
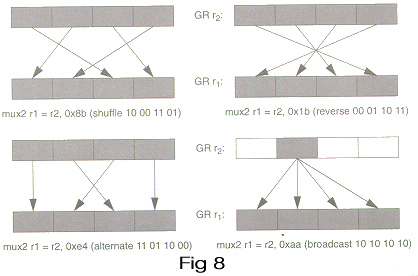
__m64 _m64_mux2(__m64 a, const int n)
Based on the value of n, a permutation is performed on a as shown in Figure 8, and the result is returned.
__m64 _m64_pavgsub1(__m64 a, __m64 b)
The unsigned data elements (bytes) of b are subtracted from the unsigned data elements (bytes) of a and the results of the subtraction are then each independently shifted to the right by one position. The high-order bits of each element are filled with the borrow bits of the subtraction.
__m64 _m64_pavgsub2(__m64 a, __m64 b)
The unsigned data elements (double bytes) of b are subtracted from the unsigned data elements (double bytes) of a and the results of the subtraction are then each independently shifted to the right by one position. The high-order bits of each element are filled with the borrow bits of the subtraction.
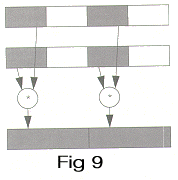
__m64 _m64_pmpy2l(__m64 a, __m64 b)
Two signed 16-bit data elements of a, starting with the most significant data element, are multiplied by the corresponding two signed 16-bit data elements of b, and the two 32-bit results are returned as shown in Figure 9.
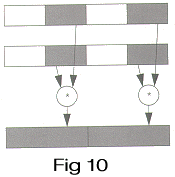
__m64 _m64_pmpy2r(__m64 a, __m64 b)
Two signed 16-bit data elements of a, starting with the least significant data element, are multiplied by the corresponding two signed 16-bit data elements of b, and the two 32-bit results are returned as shown in Figure 10.
__m64 _m64_pmpyshr2(__m64 a, __m64 b, const int count)
The four signed 16-bit data elements of a are multiplied by the corresponding signed 16-bit data elements of b, yielding four 32-bit products. Each product is then shifted to the right count bits and the least significant 16 bits of each shifted product form 4 16-bit results, which are returned as one 64-bit word.
__m64 _m64_pmpyshr2u(__m64 a, __m64 b, const int count)
The four unsigned 16-bit data elements of a are multiplied by the corresponding unsigned 16-bit data elements of b, yielding four 32-bit products. Each product is then shifted to the right count bits and the least significant 16 bits of each shifted product form 4 16-bit results, which are returned as one 64-bit word.
__m64 _m64_pshladd2(__m64 a, const int count, __m64 b)
a is shifted to the left by count bits and then is added to b. The upper 32 bits of the result are forced to 0, and then bits [31:30] of b are copied to bits [62:61] of the result. The result is returned.
__m64 _m64_pshradd2(__m64 a, const int count, __m64 b)
The four signed 16-bit data elements of a are each independently shifted to the right by count bits (the high order bits of each element are filled with the initial value of the sign bits of the data elements in a); they are then added to the four signed 16-bit data elements of b. The result is returned.
__m64 _m64_padd1uus(__m64 a, __m64 b)
a is added to b as eight separate byte-wide elements. The elements of a are treated as unsigned, while the elements of b are treated as signed. The results are treated as unsigned and are returned as one 64-bit word.
__m64 _m64_padd2uus(__m64 a, __m64 b)
a is added to b as four separate 16-bit wide elements. The elements of a are treated as unsigned, while the elements of b are treated as signed. The results are treated as unsigned and are returned as one 64-bit word.
__m64 _m64_psub1uus(__m64 a, __m64 b)
a is subtracted from b as eight separate byte-wide elements. The elements of a are treated as unsigned, while the elements of b are treated as signed. The results are treated as unsigned and are returned as one 64-bit word.
__m64 _m64_psub2uus(__m64 a, __m64 b)
a is subtracted from b as four separate 16-bit wide elements. The elements of a are treated as unsigned, while the elements of b are treated as signed. The results are treated as unsigned and are returned as one 64-bit word.
__m64 _m64_pavg1_nraz(__m64 a, __m64 b)
The unsigned byte-wide data elements of a are added to the unsigned byte-wide data elements of b and the results of each add are then independently shifted to the right by one position. The high-order bits of each element are filled with the carry bits of the sums.
__m64 _m64_pavg2_nraz(__m64 a, __m64 b)
The unsigned 16-bit wide data elements of a are added to the unsigned 16-bit wide data elements of b and the results of each add are then independently shifted to the right by one position. The high-order bits of each element are filled with the carry bits of the sums.