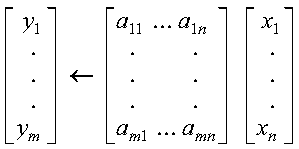

This subprogram computes the matrix-vector product for sparse matrix A, stored in compressed-matrix storage mode, using the matrix and vectors x and y:
where A, x, and y contain long-precision real numbers. You can use DSMTM to transpose matrix A before calling this subroutine. The resulting computation performed by this subroutine is then y<--ATx.
| Fortran | CALL DSMMX (m, nz, ac, ka, lda, x, y) |
| C and C++ | dsmmx (m, nz, ac, ka, lda, x, y); |
| PL/I | CALL DSMMX (m, nz, ac, ka, lda, x, y); |
The matrix-vector product is computed for a sparse matrix, stored in compressed matrix mode:
where:
It is expressed as follows:
See reference [73]. If m is 0, no computation is performed; if nz is 0, output vector y is set to zero, because matrix A contains all zeros.
If your program uses a sparse matrix stored by rows and you want to use this subroutine, you should first convert your sparse matrix to compressed-matrix storage mode by using the DSRSM utility subroutine described in DSRSM--Convert a Sparse Matrix from Storage-by-Rows to Compressed-Matrix Storage Mode.
None
This example shows the matrix-vector product computed for the following sparse matrix A, which is stored in compressed-matrix storage mode in arrays AC and KA. Matrix A is:
* *
| 4.0 0.0 7.0 0.0 0.0 0.0 |
| 3.0 4.0 0.0 2.0 0.0 0.0 |
| 0.0 2.0 4.0 0.0 4.0 0.0 |
| 0.0 0.0 7.0 4.0 0.0 1.0 |
| 1.0 0.0 0.0 3.0 4.0 0.0 |
| 1.0 1.0 0.0 0.0 3.0 4.0 |
* *
M NZ AC KA LDA X Y
| | | | | | |
CALL DSMMX( 6 , 4 , AC , KA , 6 , X , Y )
* *
| 4.0 7.0 0.0 0.0 |
| 4.0 3.0 2.0 0.0 |
AC = | 4.0 2.0 4.0 0.0 |
| 4.0 7.0 1.0 0.0 |
| 4.0 1.0 3.0 0.0 |
| 4.0 1.0 1.0 3.0 |
* *
* *
| 1 3 1 1 |
| 2 1 4 1 |
KA = | 3 2 5 1 |
| 4 3 6 1 |
| 5 1 4 1 |
| 6 1 2 5 |
* *
X = (1.0, 2.0, 3.0, 4.0, 5.0, 6.0)
Y = (25.0, 19.0, 36.0, 43.0, 33.0, 42.0)